What is synthetic data and why is it important?
There is no turning back the clock on the power, impact and future ubiquity of machine learning algorithms – which is why it’s an active investment area at AV8 Ventures. However, ML has several challenges that must be overcome to deliver on its promises. One in particular is the need for training data to fine tune traditional models. Historically, accumulating necessary training data has suffered from:
- Being expensive and slow
- Often requiring manual inspection and labeling
- Never having sufficient data to fully train models
- Significant privacy concerns
Synthetic data can overcome many of these challenges. Instead of trying to capture real data, synthetic data is fake data that is generated to be statistically similar to the underlying data that it’s trying to replace or augment. This data is usually created through a mix of inferences from trained machine learning models and procedural combinations of existing data or assets. There are primarily two categories of synthetic data that require radically different approaches to generation: structured and unstructured data.
Structured synthetic data usually refers to text, tabular, and time series data that contain some kind of relationship to each other. Privacy focused industries such as healthcare and financial have urgent needs for this as there is a regulatory friction in using the raw data due to privacy regulations. For example: a data science team at a healthcare company cannot simply retrieve personally identifiable information from a database and train models on that data without undergoing a security review process that would likely take 6 months or longer.
Unstructured synthetic data typically encompasses datasets like audio, visual and geospatial data: pictures, videos, 3D-dot maps, LiDar maps, terrain, etc. Use cases range from training self driving vehicles and robots to training perception models for object and human recognization (e.g., Apple’s FaceID)
At AV8 Ventures we have met with multiple synthetic data start-ups across a range of use cases. This article will focus on computer-vision centric unstructured synthetic data which we believe represents a huge market opportunity and solves a more acute pain point in the long tail of gathering data for computer vision perception use cases.
Market Map:
Problems unstructured synthetic data is solving:
Despite the numerous differences in startups and verticals in the space, one can summarize the objective of each down to one simple goal: to train a computer vision perception model to be more accurate in less time with less money.
“A picture is worth a thousand words.”
This is especially true when it comes to training a perception model. Computer vision is a difficult problem and it’s far from being solved, especially compared to some of the NLP and text classification models that have been released such as Large Language Models and GTP-3. As a data format, text data contains much less “fuzziness” that models have to account for.
However, for computer vision: there’s a lot of fuzziness in real world collected and labeled data that you have to account for including:
– Incomplete data (something partially blocking the object)
– Variations in camera fidelity, angles, background
– Lighting conditions and weather
As a result, recognizing even one specific object in various environments with various hardware with near 100% accuracy is never guaranteed.
The main problem that synthetic data is solving is improving performance of perception models by including rare instances and reducing bias in the dataset. Additionally, synthetic data can also overcome the privacy concerns previously described. There’s a long tail of data collection and labeling for these perception models where training requires data on rare occurrences (such as a car accident) but that data could possibly never materialize in data collection efforts. When is enough data enough? Some of the biggest self-driving companies will spend $Millions a year driving specially kitted out cars with sensors to gather real data with which to train their perception models. However, how many miles will have to be driven before an instance of a child running out into the street in front of the vehicle is recorded? What about two or three children at the same time? Gathering more data indefinitely cannot guarantee that you will ever capture this data. With autonomous simulators such as NVIDIA’s Drive Sim, Parallel Domain, and Applied Intuition, you can gather synthetic data on these rare situations without putting anyone in harm’s way.
Bias is also a huge problem for perception models. Notoriously, Google photos in 2015 labeled a black Twitter user and his friend as gorillas. This is likely a result of training a model on a dataset at Google that contained few examples of darker skinned people. Synthesis AI, for example, generates synthetic human facial data through their API where you can specify various features of the humans in the data to include features such as: skin color, ethnicity, hair type, lighting condition, viewing angle, and more. They can provide RGB pictures, 3D dot map, and even infrared versions of the data. Instead of spending a disproportionate amount of time trying to find a curly ginger hair man with glasses and freckles, data teams can retrieve synthetic data from Synthesis to round out their dataset to reduce bias.
Additional examples of how some startups are helping to solve the long tail data problem:
Simerse: Builds inspection models for physical infrastructure where defects are rare but potentially calamitous.
Neurolabs: Provides object recognition for retail applications. They use synthetic data as retail data including rare products, limited time sales (less data)
Isaac Sim (Nvidia): Robotics simulation platform that generates synthetic data including randomized lighting, environment variables, etc to help train robots in warehouse settings.
Real world data is also expensive and takes a long time to gather, label, and normalize for training. Unstructured synthetic data can short circuit that process. For example, Apple’s Face ID requires infrared data in other to create the contour map of each person’s face hence they can not simply use publicly available image datasets of people’s faces. They would have had to recruit thousands of people, have them sign waivers, set up special equipment to capture data of those faces, send it off to the labeling agency, and then finally include that in their training dataset. Companies can spend up to $2m a year on real world data collection and labeling. Synthetic data could be generated via an API call as the fastest method and through simulation and construction of a scene in a simulator as the slowest method. All without having to deal with the regulatory obstacles that come with handling real-word data.
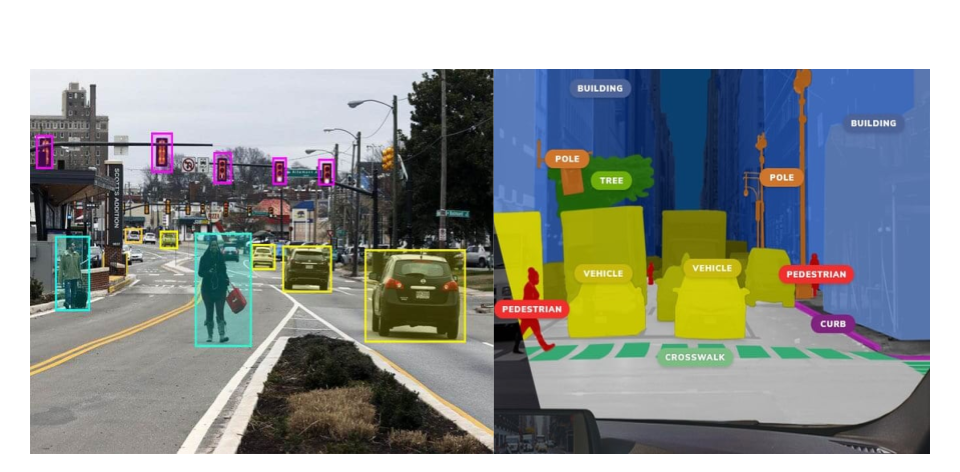
Bounding box labels from human labelers Ground truth labels from synthetic data
Lastly, unstructured synthetic data can provide labels that you cannot possibly obtain from real world data, furthering the accuracy of perception models. For self-driving data and robotics data, synthetic data can provide the ground truth of objects in the scene: exactly how far something is from the source, how big it is, the angle of the object, velocity, etc. The fidelity of labels increases from bounding boxes in manual labeling to the highest fidelity outlines of the objects in synthetic data. Neurolabs will provide transparent object placement data even if it’s blocked by another object. Synthesis AI tracks over a few hundred elements on the face.
How do startups differentiate in this space?
The most significant and obvious differentiator among startups is the vertical that they focus on. The difference in this focus will affect the technical architecture that underlies the product distribution, data types, and asset generation.
Product distribution and form tends to vary from company to company but a general rule of thumb is the more nuanced and complex the data that needs to be generated, the more control that the customers need. For example, autonomous vehicle companies need the freedom to specify specific scenarios of which to generate synthetic data from (child running in front of a car). As a result, many of the AV and robotics synthetic data companies (DRIVE Sim, Applied Intuition, Cognata, Issac Sim) build and sell applications similar to Unreal Engine or Blender, popular and powerful video game scene generators, that allow for this type of freedom. Once a scenario is programmed, the application will generate the data. Other companies such as Datagen and Rendered.ai will provide a portal through which customers can design their dataset based on external assets as well. Rendered.ai will allow you to upload your own assets from which they will generate additional data of similar likeness.
Data distribution through an API is popular for other startups and other applications (see for ex. Synthesis AI). In this model, customers would call the API with parameters that would be reflected in the returned dataset. In Synthesis AI’s case, customers can specify ethnicity, skin color/tone, lighting, and hair features as part of the the API call.
However, despite the variety of verticals and product forms, the pervasive challenge that’s echoed consistently in our conversations with synthetic data teams is the issue of scalable asset generation at low cost. This is arguably the most important ability in the tech stack of startups in this space as their growth is limited by their ability to generate assets. 3D asset artists are very expensive to hire; it’s effectively not feasible to create datasets by hand every time and if that was the only method, only the biggest companies could afford to be customers.
There are several approaches to solving this problem including:
- Manual creation by 3D artists in “traditional” modeling applications such as Unity and Blender.
- Procedural combination of existing assets for sterile objects.
- Programmatic statistical alteration of base assets. Usually for natural and variable objects such as foliage, imperfections, etc.
- Diffusion models and other generative approaches that create entirely new assets and data, typically based on keywords. This is more nascent and still in experimental phases within various companies.
To power a scalable asset generation pipeline, it’s essential to build a data warehouse of base assets and real data from which to generate new assets from. This warehouse of real data and assets becomes part of the moat that startups have in this space and is why it’s difficult to focus on more than one vertical at a time. The reusability of assets, once obtained, is infinite. However, gathering the initial real data, creating the base assets, and tailoring a synthetic data generation pipeline requires a substantial startup cost.
Challenges for growth in the market:
Synthetic data is a relatively new advancement and on a macro level, one of the challenges that the entire industry faces as a whole is skepticism. Customers are generally skeptical of incorporating synthetic data into their datasets even though studies show that a machine learning model trained on combined synthetic and real dataset attains higher accuracy than a model. In effect, ML practitioners copy-paste papers and models from academia where real model development happens. And because there is a lack of budget for researchers to gather more data, both real or synthetic, they default their research to producing better models on standardized datasets.
As the field of perception advances, another systemic risk startups face is the future development of smarter models that need less data to train. If future iterations of perception models require substantially less data to train, less synthetic data will be required as well.
Lastly, companies are also concerned about the user experience as there’s no clear market precedent. How do they build the product in a way that is thoughtful for the customer? Training with a mixed real and synthetic dataset requires you to treat the training process differently and current popular MLOps tools don’t have the features necessary to cover those differences.
Summary:
Today, data gathering and labeling to train perception models for autonomous and robotics use cases remains costly. The total cost of development for developing computer vision models is much higher than just data labeling. Unstructured synthetic data can help with virtual prototyping, shortening of the iteration cycle, and overall accuracy enhancement. It will become an increasingly important part of the ecosystem to democratize perception technology.
At AV8 Ventures, we believe that as simulation and rendering technologies improve, in the near future perception models will eventually be trained only on synthetic data.
Special thanks to all the companies and personnel who helped with our research including Synthesis AI, NVIDIA Isaac Sim, Parallel Domain and Neurolabs.


0 Comments